Google follows URLs in text
Today I learned that Google follows URLs even when they are plain text
I’m not sure I’ve ever experienced this before so I wanted to document in case it is useful to someone. It appears that Google follows URLs in text, even if they aren’t marked up as links or are clickable in any way.
Links are the foundation of the web. It is how we navigate from page A to page B, and from one site to another.
For years links have been one of the main metrics that gauge how well your web page does in search rankings. To over-simplify, if 100 other websites think this link is pretty good, it must be pretty good.
As part of our own SEO efforts on this site, every so often we check in with tools like Google Search Console (GSC), to make sure that we aren’t doing something that would negatively impact how people could find us.
One of the reports within GSC shows you which pages on your website have been found but not indexed. Indexed means available for searching within Google. Generally speaking you want to fix errors you find here, because either legitimate pages aren’t appearing in search, which is bad, or you have links to illegitimate pages which mean more work is being done that needs to be.
I will explain this second case with an example, because it what I was looking at when I spotted that Google will follow a link even if it just appears as text.
On tosbourn.com, we force everything to be https, so if you visit with http, it will redirect to https. Separate to this, over the years we have moved some pages around, so, for example if you visit /hire-me/ it will redirect to /hire-us/.
If you were to visit http://tosbourn.com/hire-me/, two different redirects happen. One to https, and then one to the new URL location.
Redirects should be avoided when possible. There are lots of reasons, my current three favourite ones are;
- Redirects are slower for the end user
- Each jump in a redirect chain could potentially fail
- You are forcing computers to do unnecessary work, wasting electricity and other resources
So, when I saw that GSC was saying http://tosbourn.com/hire-me/ couldn’t be indexed, I knew I had a link somewhere that needed updated.
When Google reports on a page, it will tell you where it found the page, the common places are;
- An internal link or redirect from your domain
- Your sitemap
- An external site
I was pretty confident it was going to be one of the first two, because why would someone be linking to our hire us page?
Well, it turns out, as the famous philosopher of our times, Taylor Swift, said, “It’s me, hi, I’m the problem, it’s me”.
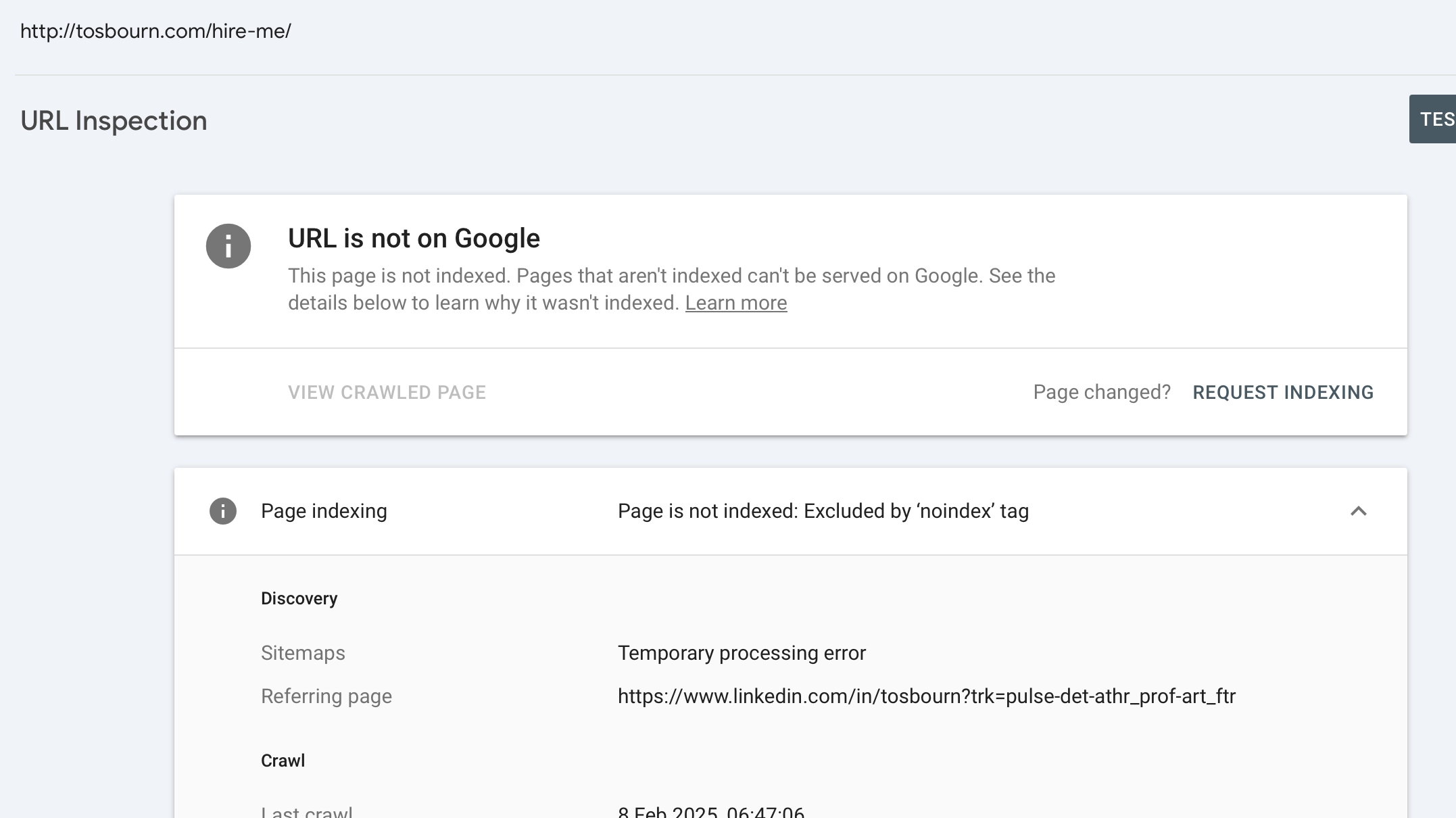
As you can see from the image above, the link was said to come from https://www.linkedin.com/in/tosbourn/, which is my personal LinkedIn page.
LinkedIn only really gives you one opportunity to add a link, and in my case it was going to our homepage, using https. So I was very confused, I couldn’t see any links. It wasn’t even appearing when viewing the source for the page.
After much clicking around, I expanded a bit of a blurb I had written about some work I’d done, and noticed I’d included the link, in plain text, at the end of the blurb.
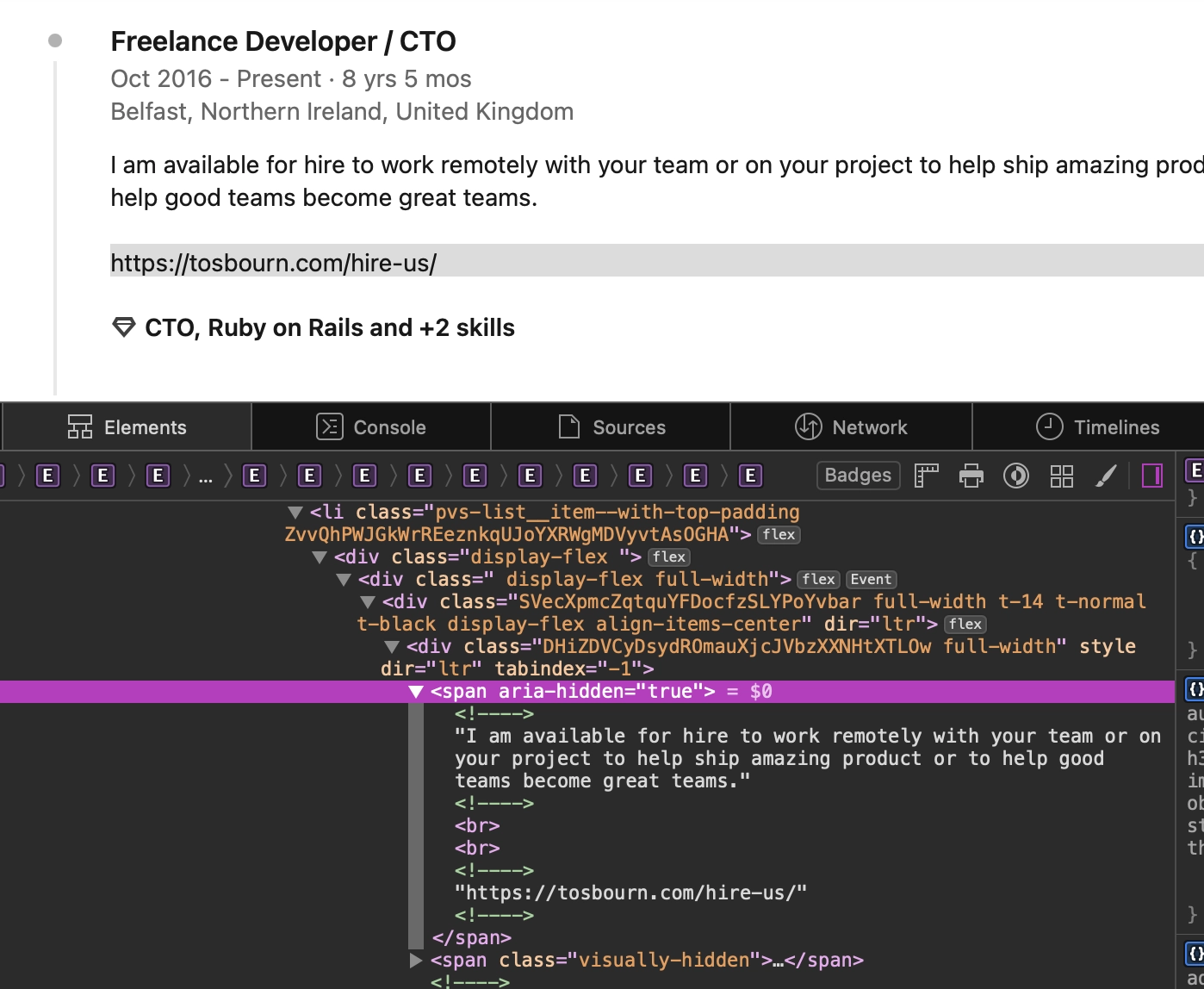
As you can see, I’ve fixed this now!
What makes the LinkedIn example extra interesting is the text is hidden behind an aria-hidden attribute.
Should Google be doing crawling URLs that just appear in text?
According to their own best practices, no;
Generally, Google can only crawl your link if it’s an
<a>HTML element (also known as anchor element) with an href attribute. Most links in other formats won’t be parsed and extracted by Google’s crawlers.
The word “Generally” is doing some heavy lifting here.
It does make sense, however, because Google wants to know about every page on the internet, and if it can parse some text and find a link-like thing, why not attempt to follow it?
Especially when it comes to parsing PDF and other text documents that aren’t always appropriately marked it, it would make sense that they can guess that the words being used are likely talking about a URL.
What does Google crawling URLs in text mean for SEO?
Probably not a lot. I wouldn’t personally rely on this as a way to build links, I’m unsure what, if any, value Google places on such a link. Certainly in GSC’s eyes it was a link.
It does mean you will potentially need to deal with incoming links that aren’t really links in reports such as those made by GSC.
What does Google crawling URLs in text mean for text authoring?
I think this is a more interesting point. There have been times when I’ve wanted to send a signal that I don’t want to contribute to a website’s link profile, but I will still mention the URL as text, to provide context to the reader.
Knowing that Google will attempt to crawl this text anyway will make me rethink this strategy, for two reasons.
- I don’t want machines to waste time doing something they don’t need to do.
- If the end result is still a link Google will crawl, there is no reason to not be explicit about it and make it a
<a>.